Getting Started
Introduction
Leverage Tavus tools and guides to give your AI Agent real-time human-like perception and presence, bringing the human layer to AI.
Developer Guides
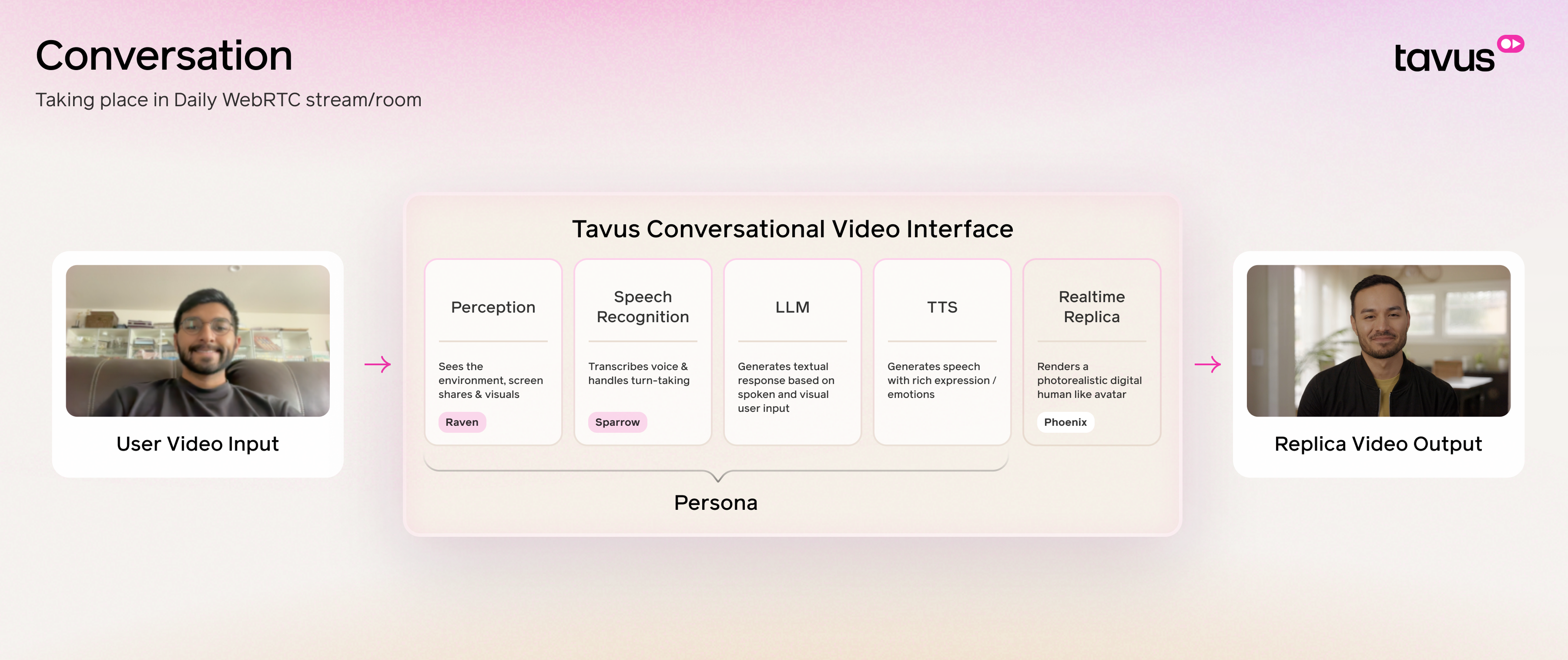
Follow our in-depth technical resources to help you build, customize, and integrate with Tavus:Conversational Video Interface
Learn how Tavus turns AI into conversational video.
Persona
Configure the Persona’s layer to define the AI’s behavior.
Replica
Build hyper-realistic digital human using Phoenix.
Conversational Use Cases

Tavus Researcher
A friendly AI human who is also a researcher at Tavus.

AI Interviewer
Screen candidates at scale with an engaging experience.

History Teacher
Offer personalized lessons tailored to your learning style.

Sales Coach
Offer scalable 1:1 sales coaching.

Health Care Consultant
Offer consultations for general health concerns.

Customer Service Agent
Support users with product issues.